This is the foundation page for Topical Analysis. Also, see my Standard Caution About Abstractions.
In the System Engineering context, I use the word “topic” to mean “a qualitative descriptor of an object or process”. In all cases, the topic answers the “what is that about?” question in regard to a piece of un-structured information. Because topics are qualitative, they are expressed with text rather than numbers: by definition1, a topic cannot have a number directly related to it. That information gets addressed during subsequent parameterization.
Types of topics include functions (“open the door”, “maintain the internal temperature”), physical characteristics (“reflectance”, “inertial properties”, “form”), mission circumstances (“posture”, “opposing force composition”) and interfaces (“power pinout”, “bolt pattern”). Usage includes things like “Should we allow the hatch door to just slam open?”, “The dynamics group needs to constrain the tolerance on spacecraft inertial properties”, “This targeting sensor can stare at a laydown spanning 17° in the horizontal”, and “what’s the hole pattern where the widget sits on the bulkhead?”.
Preliminary Analysis of Topics, with Topical Classification
I usually build a list of topics during my initial survey of the documentation (which might, or might not, be a Compilation exercise) available when first starting a project2. I usually conduct that survey in conjunction with my initial pass at Configuration Identification. Performing these two operations in concert allows me to simultaneously consider what the pieces are and what characteristic topics distinguish each piece3 from others. It also allows early identification of some important issues before things get out of hand. Examples include4:
– If I find myself trying to describe something I have not yet identified, or unable to supply so much as a single descriptor for something I think should exist, then I know I have an issue to resolve.
– If I find myself repeating a set of descriptors, then I’ve probably duplicated an entity under more than one nomenclature.
– If I find myself wanting to re-use nomenclature with a different set of descriptors, then I’m usually on the verge of eliminating a source of confusion.
– If I find several entities sharing a significant subset of descriptors, there’s potential for commonality or CI classification5.
This is a naturally iterative process, but usually converges quickly. Execution of this preliminary process will frequently discard, merge, spawn, or split items and their associated sets of topics. Failure to converge is cause for calling into question the coherence of the documentation or the perspicacity of the analyst6.
Maintaining the descriptors in list form quickly renders the raw mental process of considering duplication and contradiction overwhelming, so a bit of organizational strategy is called for. I usually classify the descriptors into a dendrogram, making one such diagram for each item being identified, a sample of which is shown in Figure 1. Note that the sample doesn’t actually show any detailed topics: it only identifies clusters of topics. This set of clusters is the primary output of the preliminary analysis.
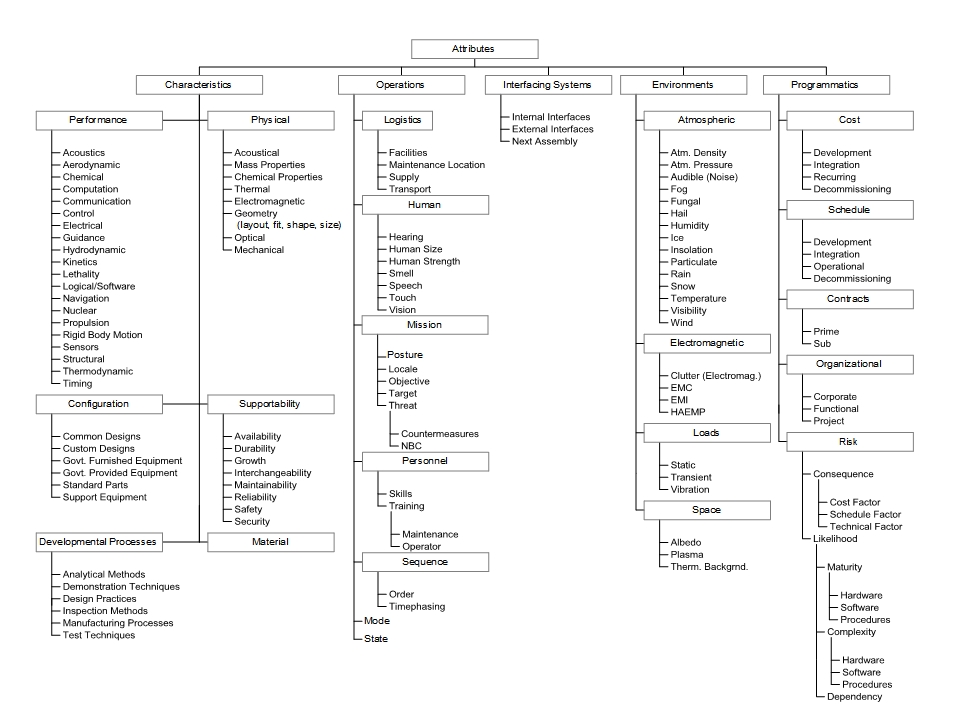
The reader will note that the nomenclatures at the “leaves” of Figure 1 bear a striking similarity to broad areas of commonly-defined Engineering and Operational expertise. This is by intent: such a set of “headings” is also my first foray into identifying the flavors of Engineer I will need in order to deal with the technical material at hand. In fact, I will quite literally identify clusters while keeping an odd eye on my company’s list (and definitions) of Engineering skills, just to keep me on the straight and narrow path7. It should also be noted that, while similar terms might appear under more than one “boxed” header, each cluster name is unique on the chart.
Clustering by skill-related nomenclature also makes it much easier to identify redundancies, overlaps, and inconsistencies in the identification of topics8. Clarity with regard to those issues is further enhanced during identification of the specific measures associated with topics, and that notion correctly suggests that there is some iteration between identification of topics and parameterization thereof. As the list of topics is propagated to the various specialists, each will usually review their area for these issues, helping to assure orthogonality of the set.
I maintain nomenclature across charts so that any given term is global within any given project. This also allows me to horizontally “drill” across different charts (and, therefore, different items) to appreciate how similar things are being dealt with across the system. You could think of the charts, taken together, as if they were really elements of a single chart that showed both decomposition and characterization…but that chart would be getting pretty complicated9.
Aside
I include Figure 1 here with a certain trepidation and (therefore) an important caveat: I have seen the specific entries shown in Figure 1 interpreted as definitive, which is not my intent. While the “boxed” items have been stable for many years10, entries below that level should be established based on the nature of the system(s) being developed, coordinating between the identification of CI’s and their descriptors. Consistent use of a descriptor diagram allows most of my search for duplicated sets of descriptors to be conducted within one “box” at a time11.
Topical Assignment
As noted above, topical clusters are a primary output of the preliminary process. It is important to understand why this needs to be so: a comprehensive topical analysis performed by a single individual is subject to severe cognitive biases12. Mitigation of those biases requires such details to be processed by a larger group of people operating in concert, and that process needs to have a built-in mechanism for managing both the topics and the clusters.
Because the assignment process needs to involve a larger group of people, it is useful to document the process (at least, informally). I usually create that process interactively with the group, so that they have a common interpretation of why the various paths exist. This also means they feel a certain ownership in the process, and are more likely to discuss and propose changes to that basic process.
Figure 2 shows an example Topical Assignment process used on an (anonymous) requirements extraction project almost 20 years ago. The flow shown is actually the “mature” version: we started with a simpler flow drawn on a white board. Because of the specific mental postures of the personnel involved, it is depicted as a cycle in which any given requirement could be operated on more than once; the specific objective (not shown actually shown on the chart) was to exhaustively show that no single requirement spoke to the same topic as any other requirement for any single Configuration Item13.
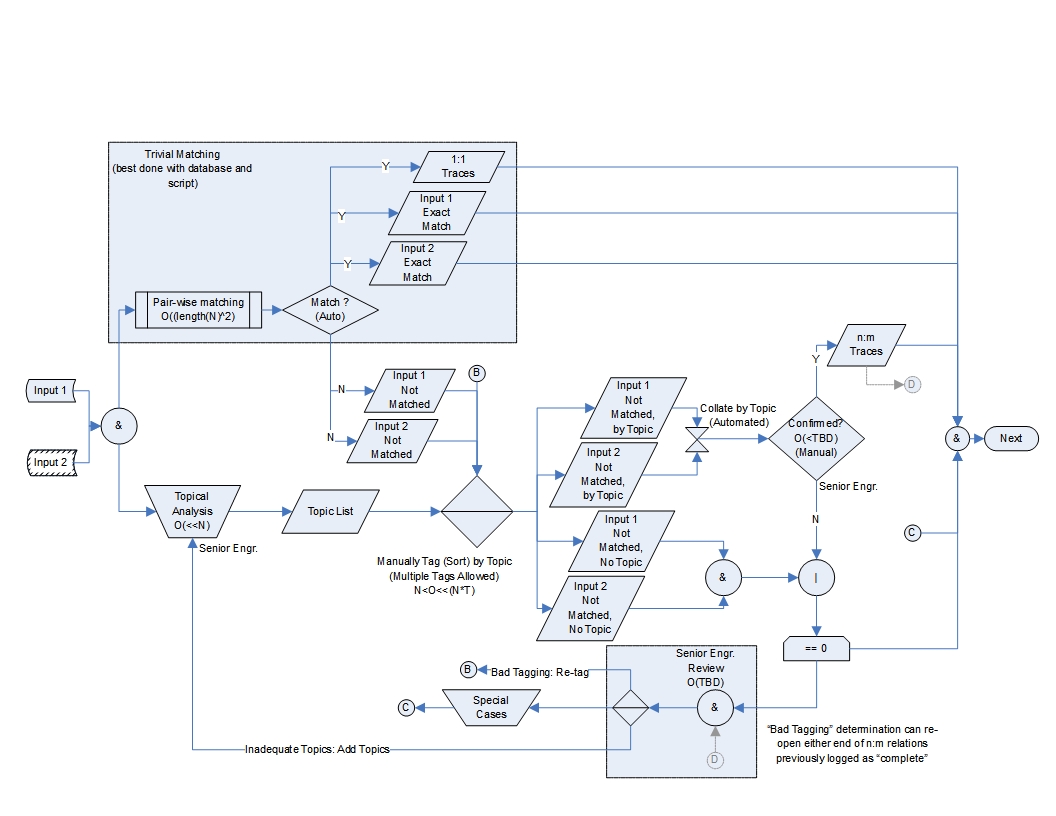
Figure 2 has several features of particular interest:
- The process admits to the startup transient
- When there are no topics (yet), most of the diagram is trivial, which leads to the “Add Topics” branch. The process did (however) execute in the presence of a dendrogram very much like the one shown in Figure 1, so the slate was never completely clean.
- When there are topics, but none has been assigned to a given input text, the text was manually tagged with one or more topics14; in that case, the process was executed without the optional “Input 2”.
- The process admits to correction in the event that topics are altered (“Bad Tagging” and “Re-tag”). This was actually managed with a fully Relational Database implemented specifically for this process. The database automated the issue of catching of requirements tagged with obsolete topics.
- The process became more automated as it progressed, with the final output being generated from the database.
- The process sheet allowed us to maintain a crude running estimate of “work to go”15 ; the estimate converged to within a few percent less than half-way through our first pass because we randomized the order in which the inputs were subjected to the process (so that the list of detailed topics stabilized early).
In the particular exercise for which Figure 2 was created, three or four of us processed around 5000 proposed requirements in about 5 days. When complete, we were reasonably certain we had a comprehensive list of the topics on which requirements should be written and any one of us had a good shot at explaining the whys and wherefores of each topic. We were also well on our way to identifying the Engineering skills necessary to allocate the requirement measures that were appropriately in-scope to our contract.
As with Figure 1, I include Figure 2 here with caveats: the assignment analysis can occur in contexts other than this one, using other tools for automation, with different skills and aptitudes present. In particular, the logistics of executing such processes without a properly-designed database and User Interface16 can quickly overwhelm the engaged staff. Figure 2 should, therefore, not be taken as an authoritative process flow.
Assignment of this general type continues through at least the end of Preliminary Design, with each layer of requirements decomposition, and with the characterization of each Interface as it is negotiated.
Aside
My discussion of Figure 2 alluded to implementation of a Relational Database, which is consistent with my general practice. From that perspective, a “topic” is (and should be) a fairly persistent object class once it has been authoritatively established on a project (i.e., placed under Configuration Control). As the project evolves, the specific measures used to quantify that topic might be more transient, and their values more transient still…but as we approach the end of the project, we should still be working with pretty much the same topics as when we started!
Structure
Based on the foregoing, a minimum set of data elements can be defined (see Table 1). Additional elements may prove useful, depending on implementation. Note that, in common usage, the nomenclature might be combined with some form of the Allocation Target in order to distinguish it from topics for other dingae17. This suggests (correctly) that there might be significant utility from a common, abstract set.
| Element Name | Description |
| Allocation Target | The dingus (or set of interfacing dingae) being described. |
| Nomenclature | A noun-phrase used to identify the item. |
| Description | Enough words to succinctly indicate the intended concept. |
| *Source | Pointer to the input material leading to definition of the topic. |
| Rationale | Succinct description of the logic leading to definition. |
- as “qualitative”[↩]
- This is an “analysis” process because it decomposes the emerging system into constituent parts and starts to identify certain kinds of relationship between them. Technically, the analysis domain in question is “ontological”, but we also use semantics as an important tool.[↩]
- Or, sometimes, class of pieces.[↩]
- but certainly are not limited to![↩]
- shared requirements between two or more items that differ in some of their details.[↩]
- or both.[↩]
- That list of skill codes represents the technical domains the company claims to be able to manage. That’s a pretty handy concept![↩]
- i.e., orthogonality and correctness.[↩]
- Technically, it would be mixing two different paradigms (dimensions) of decomposition in the same breakdown, which is rarely a good idea.[↩]
- generally being taken from the types of characteristics discussed in MIL-STD-490 and other standards of it’s era.[↩]
- The dendrogram concept can be extended during parameterization of the system.[↩]
- e.g., framing, anchoring, and “Pride of Authorship”[↩]
- We were looking for contradictions at the time, in order to construct a parsimonious set of requirements within a specific topical area.[↩]
- I write no general rule saying a miscellaneous piece of text can address only one topic. For certain types of textual data, such a constraint will be written elsewhere.[↩]
- The “O” stands for “Order”, meaning that we estimated the number of beans yet to be dispositioned[↩]
- Ours was drag-and-drop, modeling the dendrogram shown in Figure 1.[↩]
- e.g., “The door’s weight”.[↩]